什么是算法开发¶
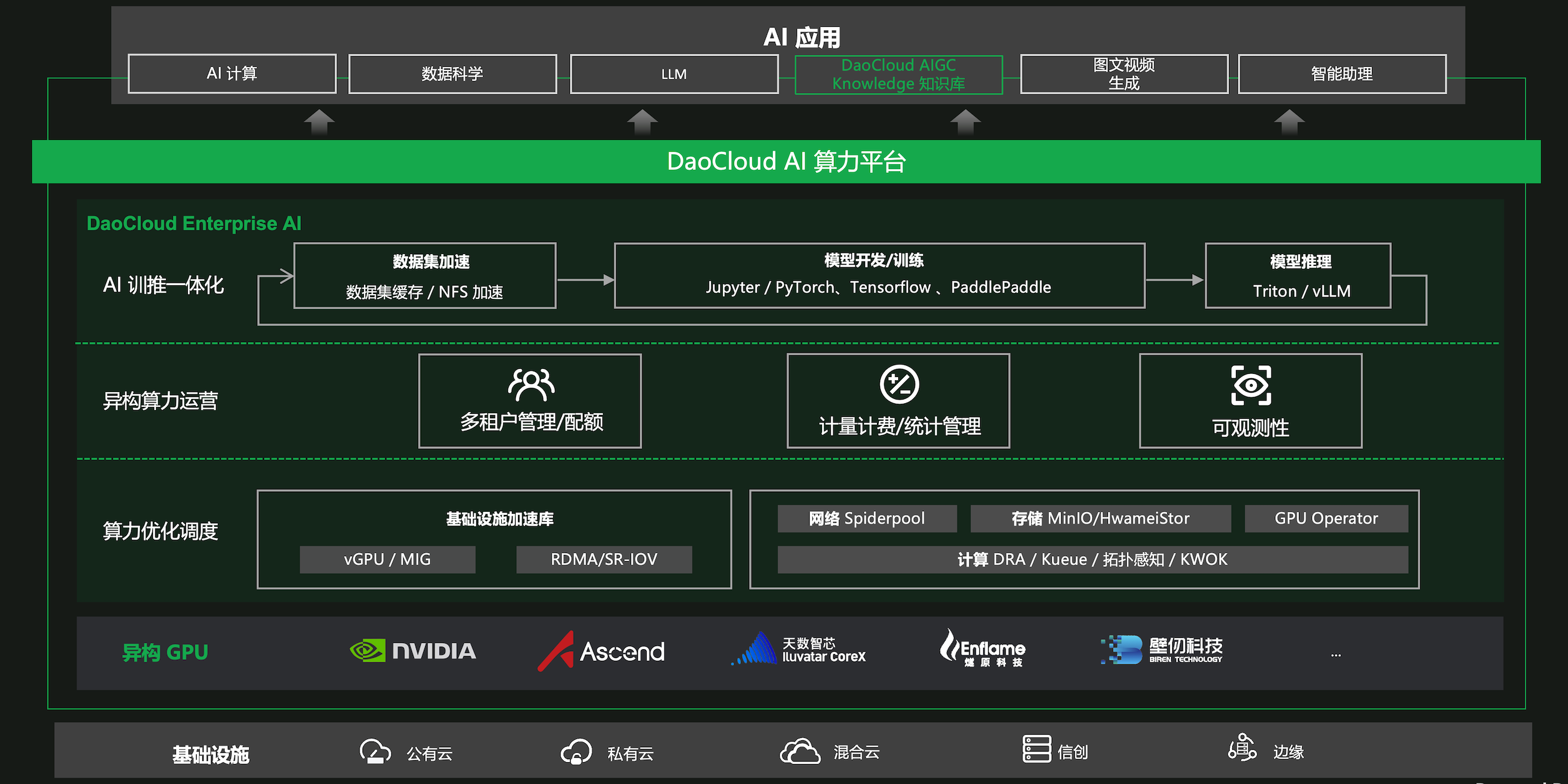
d.run 算法开发是 DaoCloud 推出的基于云原生操作系统的 AI 算力平台,能够提供软硬一体的 AI 智算体验, 整合异构算力,优化 GPU 性能,实现算力资源统一调度和运营,最大化算力效用并降低算力开销, 并且还提供了优化的 AI 开发框架,简化 AI 开发和部署,加速推动各行业的 AI 应用场景落地。
功能特性¶
- 算力资源全托管 :依托于 DCE(DaoCloud Enterprise),提供强大的基础设施能力,支持超大规模算力集群、异构 GPU 等一站式托管,并提供一系列如 vGPU 等软硬一体加速方案。
- 数据编排 :支持模型开发生命周期中数据管理与编排能力,提供多数据源接入,数据集管理、超大训练数据预热等能力,并且从底层存储引擎优化,保障数据的安全与高效利用。
- 开发管理 :提供主流的模型开发工具,满足 MLOps 和 LLMOps 工程师和科学家们对开发工具的需求,支持快速拉起高性能开发环境,一键申请高性能 GPU、软件依赖、训练数据等资源。
- 任务管理 :支持训练任务的全生命周期管理,提供多种快速创建任务的方式;支持 Pytorch、TensorFlow、PaddlePaddle 等主流任务框架,天然支持单机、分布式、多节点、多卡等多种类任务调度。
- 模型推理 :提供便捷的模型服务 Serving 能力,支持传统 NLP 模型应用和LLM 大模型一键部署,自带模型安全、审计等管理能力,支持模型服务的弹性扩容与持续可观测监控预警。
- 运维看板 :支持监控看板,算力资源与任务资源一览无余,实现全自动平台可观测,更提供详细的指标监控与运维产品能力。
- GPU 管理 :支持自动化 GPU 硬件发现,实现 GPU 套件全自动安装,用户无需处理繁琐的 GPU 驱动、CUDA 等部署工作,提供提供统一 GPU 资源看板与 调度情况分析。
- 队列管理 :支持大模型算力资源的统一调度队列管理平台,支持用户全自动队列隔离能力,实现不同业务与算力需求互不干扰,从基础设施层面实现数据与算力资源安全隔离。
逻辑架构图