DBRX Introduction: A New, Powerful Open Source LLM Model¶
Reprinted from databricks

Today, we are excited to introduce DBRX, an open universal LLM created by Databricks. In a series of standard benchmark tests, DBRX has set new technical standards among established open LLMs. Furthermore, it provides capabilities that were previously limited to closed-source model APIs for the open community and enterprises building their own LLMs; according to our measurements, it surpasses GPT-3.5 and competes with Gemini 1.0 Pro. It is a particularly powerful code model that outperforms the specialized CodeLLaMA-70B model in programming, in addition to its advantages as a general-purpose LLM.
This technological advancement comes with significant improvements in training and inference performance. With its fine-grained mixture of experts (MoE) architecture, DBRX has made groundbreaking progress in efficiency among open models. Its inference speed is twice that of LLaMA2-70B, while the total and active parameter counts of DBRX are only 40% of Grok-1. When hosted on Mosaic AI Model Serving, DBRX can generate text at a rate of 150 tokens per second per user. Our customers will find that training an MoE model requires about twice the FLOP efficiency compared to training a dense model of the same final model quality. From start to finish, our overall DBRX formula (including pre-training data, model architecture, and optimization strategies) achieves the same quality as our previous generation MPT models with nearly four times the computational resources.
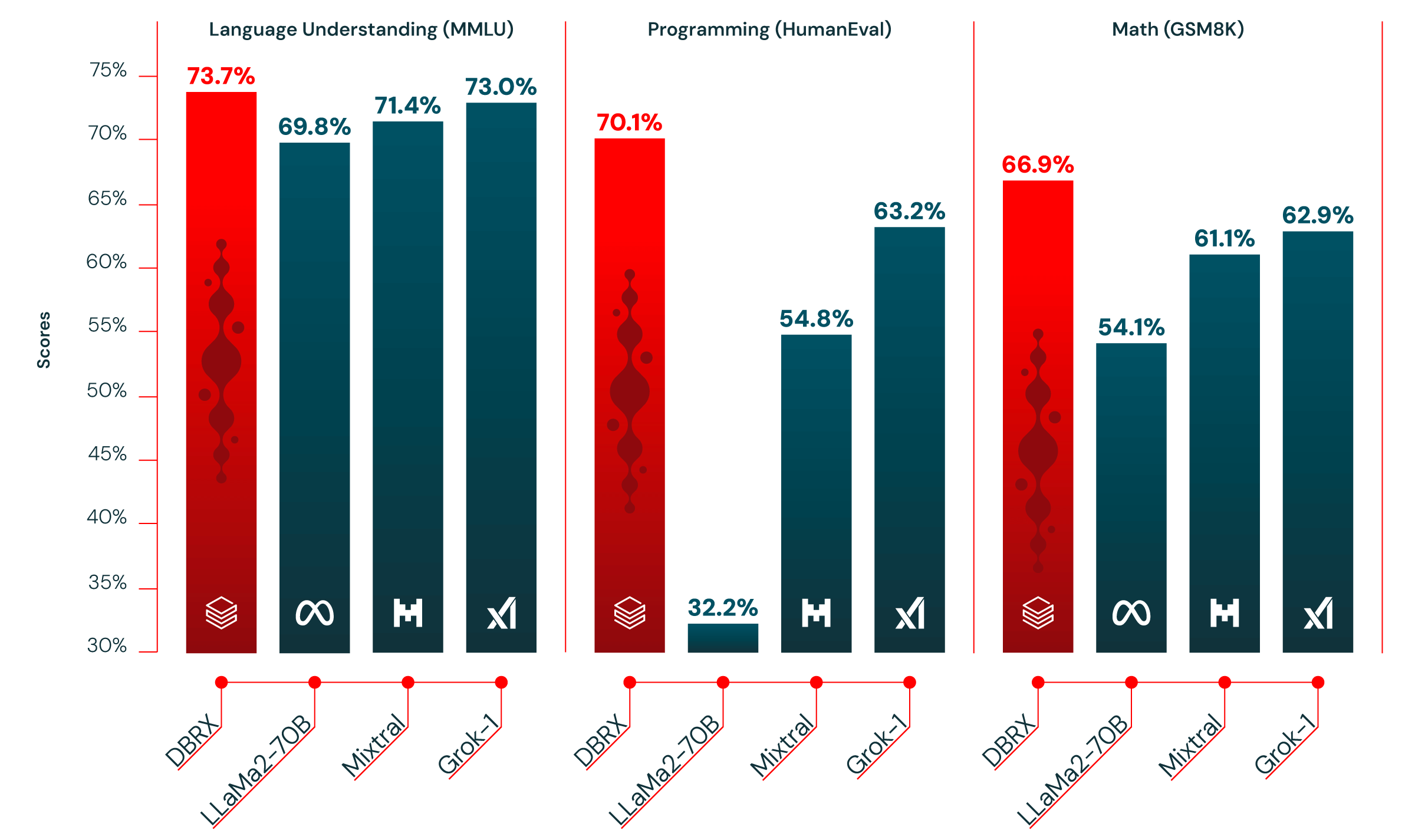
Figure 1: DBRX outperforms established open models in language understanding (MMLU), programming (HumanEval), and mathematics (GSM8K).
The weights of the base model (DBRX Base) and fine-tuned model (DBRX Instruct) are available on Hugging Face under an open license. Starting today, DBRX is accessible to Databricks customers via API, and Databricks customers can pre-train their own DBRX-like models from scratch or continue training using one of our checkpoints, employing the same tools and scientific methods we used to build the model. DBRX has already been integrated into our GenAI-powered products, where early versions have surpassed GPT-3.5 Turbo in applications such as SQL and are competing with GPT-4 Turbo. It is also a leading model in RAG tasks among open models and GPT-3.5 Turbo.
Training mixture of experts models is challenging. We had to overcome various scientific and performance challenges to build a robust pipeline capable of repeatedly training DBRX-like models efficiently. Now that we have achieved this, we possess a unique training stack that allows any enterprise to train world-class MoE base models from scratch. We look forward to sharing this capability with our customers and sharing our lessons learned with the community.
Download DBRX from Hugging Face (DBRX Base, DBRX Instruct), try DBRX Instruct in our HF Space, or check out our model repository on GitHub: databricks/dbrx.
What is DBRX?¶
DBRX is a transformer-based decoder-only large language model (LLM) trained using next-token prediction. It employs a fine-grained mixture of experts (MoE) architecture, with a total of 132 billion parameters, of which 36 billion parameters are active for any input. It has been pre-trained on 12 trillion tokens of text and code data. Compared to other open MoE models like Mixtral and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and selects 4 of them, while Mixtral and Grok-1 have 8 experts and select 2. This provides 65 times more combinations of experts, which we found can improve model quality. DBRX uses rotary positional encoding (RoPE), gated linear units (GLU), and grouped query attention (GQA). It employs the tokenizer from GPT-4, which is available in the tiktoken repository. We made these choices based on extensive evaluations and scaling experiments.
DBRX has been pre-trained on a carefully curated dataset of 12 trillion tokens, with a maximum context length of 32k tokens. We estimate that this data is at least twice as good per token compared to the data used to pre-train the MPT series models. Using the full Databricks toolkit, including Apache Spark™ and Databricks notebooks for data processing, Unity Catalog for data management and governance, and MLflow for experiment tracking, we developed this new dataset. We employed curriculum learning in the pre-training phase, altering the data mix throughout training, which we found significantly enhances model quality.
Quality Comparison with Leading Open Models in Benchmark Tests¶
Table 1 shows the quality of DBRX Instruct compared to leading established open models. DBRX Instruct leads in composite benchmark tests, programming and math benchmarks, and MMLU. It surpasses all chat or instruction fine-tuned models on standard benchmark tests.
Composite Benchmark Tests. We evaluated DBRX Instruct and other models on two composite benchmark tests: the Hugging Face Open LLM Leaderboard (average scores for ARC-Challenge, HellaSwag, MMLU, TruthfulQA, WinoGrande, and GSM8k) and the Databricks Model Gauntlet (over 30 tasks covering world knowledge, common sense reasoning, language understanding, reading comprehension, symbolic problem-solving, and programming).
In the models we evaluated, DBRX Instruct scored highest on both composite benchmark tests: Hugging Face Open LLM Leaderboard (74.5%, with the next highest model being Mixtral Instruct at 72.7%) and Databricks Gauntlet (66.8%, with the next highest model being Mixtral Instruct at 60.7%).
Programming and Mathematics. DBRX Instruct performs particularly well in programming and mathematics. In HumanEval (70.1%, Grok-1 at 63.2%, Mixtral Instruct at 54.8%, and the best-performing variant of LLaMA2-70B at 32.2%) and GSM8k (66.9%, Grok-1 at 62.9%, Mixtral Instruct at 61.1%, and the best-performing variant of LLaMA2-70B at 54.1%), its scores exceed those of all other open models we evaluated. Despite Grok-1 having 2.4 times the number of parameters as DBRX, DBRX outperformed Grok-1 on HumanEval, even though DBRX Instruct was designed for general-purpose use (Meta reported a score of 70.1% on HumanEval for the CodeLLaMA model, which was specialized for programming, yielding a score of 67.8%).
MMLU. DBRX Instruct scored higher on MMLU than all other models we considered, achieving a score of 73.7%.
| Model | DBRX Instruct | Mixtral Instruct | Mixtral Base | LLaMA2-70B Chat | LLaMA2-70B Base | Grok-1 |
|---|---|---|---|---|---|---|
| Open LLM Leaderboard (average of below 6 rows) | 74.5% | 72.7% | 68.4% | 62.4% | 67.9% | — |
| ARC-challenge 25-shot | 68.9% | 70.1% | 66.4% | 64.6% | 67.3% | — |
| HellaSwag 10-shot | 89.0% | 87.6% | 86.5% | 85.9% | 87.3% | — |
| MMLU 5-shot | 73.7% | 71.4% | 71.9% | 63.9% | 69.8% | 73.0% |
| Truthful QA 0-shot | 66.9% | 65.0% | 46.8% | 52.8% | 44.9% | — |
| WinoGrande 5-shot | 81.8% | 81.1% | 81.7% | 80.5% | 83.7% | — |
| GSM8k CoT 5-shot maj@13 | 66.9% | 61.1% | 57.6% | 26.7% | 54.1% | 62.9% (8-shot) |
| Gauntlet v0.34 (average of 30+ diverse tasks) | 66.8% | 60.7% | 56.8% | 52.8% | 56.4% | — |
| HumanEval 0-Shot, pass@1 (Programming) | 70.1% | 54.8% | 40.2% | 32.2% | 31.0% | 63.2% |
Table 1. Quality of DBRX Instruct compared to leading open models. For details on how the numbers were collected, see the footnotes. Bold and underlined indicate the highest scores.
Quality Comparison with Leading Closed-Source Models in Benchmark Tests¶
Table 2 shows the quality of DBRX Instruct compared to leading closed-source models. Based on scores reported by each model's creators, DBRX Instruct surpasses GPT-3.5 (as described in the GPT-4 paper) and competes with Gemini 1.0 Pro and Mistral Medium.
In nearly all benchmark tests we considered, DBRX Instruct either surpassed or matched GPT-3.5. DBRX Instruct outperformed GPT-3.5 on MMLU (overall score of 73.7% vs. 70.0% for GPT-3.5), as well as on common sense reasoning tasks like HellaSwag (89.0% vs. 85.5%) and WinoGrande (81.8% vs. 81.6%). DBRX Instruct excels in programming and mathematical reasoning, scoring particularly well on HumanEval (70.1% vs. 48.1%) and GSM8k (72.8% vs. 57.1%). DBRX Instruct competes with Gemini 1.0 Pro and Mistral Medium. DBRX Instruct scores higher than Gemini 1.0 Pro on Inflection Corrected MTBench, MMLU, HellaSwag, and HumanEval, while Gemini 1.0 Pro is stronger on GSM8k. DBRX Instruct and Mistral Medium have similar scores on HellaSwag, while Mistral Medium is stronger on Winogrande and MMLU, and DBRX Instruct is stronger on HumanEval, GSM8k, and Inflection Corrected MTBench.
| Model | DBRX Instruct | GPT-3.5 | GPT-4 | Claude 3 Haiku | Claude 3 Sonnet | Claude 3 Opus | Gemini 1.0 Pro | Gemini 1.5 Pro | Mistral Medium | Mistral Large |
|---|---|---|---|---|---|---|---|---|---|---|
| MT Bench (Inflection corrected, n=5) | 8.39 ± 0.08 | — | — | 8.41 ± 0.04 | 8.54 ± 0.09 | 9.03 ± 0.06 | 8.23 ± 0.08 | — | 8.05 ± 0.12 | 8.90 ± 0.06 |
| MMLU 5-shot | 73.7% | 70.0% | 86.4% | 75.2% | 79.0% | 86.8% | 71.8% | 81.9% | 75.3% | 81.2% |
| HellaSwag 10-shot | 89.0% | 85.5% | 95.3% | 85.9% | 89.0% | 95.4% | 84.7% | 92.5% | 88.0% | 89.2% |
| HumanEval 0-Shot pass@1 (Programming) | 70.1% temp=0, N=1 | 48.1% | 67.0% | 75.9% | 73.0% | 84.9% | 67.7% | 71.9% | 38.4% | 45.1% |
| GSM8k CoT maj@1 | 72.8% (5-shot) | 57.1% (5-shot) | 92.0% (5-shot) | 88.9% | 92.3% | 95.0% | 86.5%(maj1@32) | 91.7% (11-shot) | 66.7% (5-shot) | 81.0% (5-shot) |
| WinoGrande 5-shot | 81.8% | 81.6% | 87.5% | — | — | — | — | — | 88.0% | 86.7% |
Table 2. Quality of DBRX Instruct compared to leading closed-source models. Except for Inflection Corrected MTBench (data we measured ourselves at the model endpoints), all other numbers are reported by the creators of these models in their respective white papers. For details, see the footnotes.
Quality in Long Context Tasks and RAG¶
DBRX Instruct used a context window of up to 32K tokens during training. Table 3 compares its performance on a set of long context benchmark tests (KV-Pairs and HotpotQAXL from the Lost in the Middle paper, which modifies HotPotQA to extend tasks to longer sequence lengths) with Mixtral Instruct and the latest versions of GPT-3.5 Turbo and GPT-4 Turbo APIs. GPT-4 Turbo is generally the best model in these tasks. However, with one exception, DBRX Instruct outperforms GPT-3.5 Turbo across all context lengths and parts of the sequences. Overall, the performance of DBRX Instruct is similar to that of Mixtral Instruct.
| Model | DBRX Instruct | Mixtral Instruct | GPT-3.5 Turbo (API) | GPT-4 Turbo (API) |
|---|---|---|---|---|
| Answer in the first third of the context | 45.1% | 41.3% | 37.3%* | 49.3% |
| Answer in the middle third of the context | 45.3% | 42.7% | 37.3%* | 49.0% |
| Answer in the last third of the context | 48.0% | 44.4% | 37.0%* | 50.9% |
| 2K context | 59.1% | 64.6% | 36.3% | 69.3% |
| 4K context | 65.1% | 59.9% | 35.9% | 63.5% |
| 8K context | 59.5% | 55.3% | 45.0% | 61.5% |
| 16K context | 27.0% | 20.1% | 31.7% | 26.0% |
| 32K context | 19.9% | 14.0% | — | 28.5% |
Table 3. Average performance of models on KV-Pairs and HotpotQAXL benchmark tests. Bold indicates the highest score. Underline indicates the highest score excluding GPT-4 Turbo. GPT-3.5 Turbo supports a maximum context length of 16K, so we could not evaluate it on 32K. The averages for the beginning, middle, and end of GPT-3.5 Turbo are based only on contexts not exceeding 16K.
Using RAG (retrieval-augmented generation) is one of the most popular methods for leveraging model context. In RAG, content relevant to the prompt is retrieved from a database and provided to the model along with the prompt to give it more information than it would have on its own. Table 4 shows the quality of DBRX in two RAG benchmark tests (Natural Questions and HotPotQA) when the model also provided the top 10 passages retrieved using the embedding model bge-large-en-v1.5 from a Wikipedia article corpus. DBRX Instruct competes with open models like Mixtral Instruct and LLaMA2-70B Chat, as well as the current version of GPT-3.5 Turbo.
| Model | DBRX Instruct | Mixtral Instruct | LLaMa2-70B Chat | GPT 3.5 Turbo (API) | GPT 4 Turbo (API) |
|---|---|---|---|---|---|
| Natural Questions | 60.0% | 59.1% | 56.5% | 57.7% | 63.9% |
| HotPotQA | 55.0% | 54.2% | 54.7% | 53.0% | 62.9% |
Table 4. Performance of models when provided with the top 10 passages retrieved from the Wikipedia corpus using bge-large-en-v1.5. Accuracy is measured by matching the model's answers. Bold indicates the highest score. Underline indicates the highest score excluding GPT-4 Turbo.
Training Efficiency¶
Model quality must be viewed in the context of training and usage efficiency. This is especially important at Databricks, as we build models like DBRX to establish processes for customers to train their own foundational models.
We found that training mixture of experts models offers significant improvements in training efficiency (Table 5). For example, training a smaller member of the DBRX family, called DBRX MoE-B (23.5B total parameters, 6.6B active parameters), required 1.7 times fewer FLOPs to achieve a score of 45.5% on the Databricks LLM Gauntlet than the FLOPs required for LLaMA2-13B to achieve a score of 43.8%. The number of active parameters in DBRX MoE-B is also only half that of LLaMA2-13B.
Overall, our end-to-end LLM pre-training process has become nearly more efficient over the past ten months. On May 5, 2023, we released MPT-7B, a 7B parameter model trained on 1 trillion tokens that achieved a score of 30.9% on the Databricks LLM Gauntlet. A member of the DBRX family, called DBRX MoE-A (7.7B total parameters, 2.2B active parameters), achieved a score of 30.5% on the Databricks Gauntlet, requiring 3.7 times fewer FLOPs than MPT-7B to achieve a score of 30.9%. This efficiency improvement is the result of many enhancements, including the use of MoE architectures, other architectural changes to the network, better optimization strategies, better tokenization, and, importantly, better pre-training data.
Independently, better pre-training data has a significant impact on model quality. We trained a 7B model (called DBRX Dense-A) using DBRX pre-training data on 1 trillion tokens. It achieved a score of 39.0% on the Databricks Gauntlet, while MPT-7B scored 30.9%. We estimate that our new pre-training data is at least twice as good per token compared to the data used to train MPT-7B. In other words, we estimate that only half the number of tokens is needed to achieve the same model quality. We confirmed this by training DBRX Dense-A with 500 billion tokens; it outperformed MPT-7B on the Databricks Gauntlet, achieving a score of 32.1%. Besides better data quality, another significant contributor to token efficiency may be the tokenizer from GPT-4, which has a large vocabulary and is considered particularly efficient in token efficiency. These insights about improving data quality directly translate into practices and tools for our customers to train foundational models based on their own data.
| Model | Total Parameters | Active Parameters | Gauntlet Score | Relative FLOP |
|---|---|---|---|---|
| DBRX MoE-A | 7.7B | 2.2B | 30.5% | 1x |
| MPT-7B (1T tokens) | — | 6.7B | 30.9% | 3.7x |
| DBRX Dense-A (1T tokens) | — | 6.7B | 39.0% | 3.7x |
| DBRX Dense-A (500B tokens) | — | 6.7B | 32.1% | 1.85x |
| DBRX MoE-B | 23.5B | 6.6B | 45.5% | 1x |
| LLaMA2-13B | — | 13.0B | 43.8% | 1.7x |
Table 5. Details of several test articles we used to validate the DBRX MoE architecture and end-to-end training process.
Inference Efficiency¶
Figure 2 shows the end-to-end inference efficiency provided for DBRX and similar models using NVIDIA TensorRT-LLM on our optimized service infrastructure and at 16-bit precision. We aim for this benchmark to be as close to actual usage scenarios as possible, including multiple users simultaneously accessing the same inference server. We generate a new user every second, with each user request containing approximately 2000 tokens of prompts and each response containing 256 tokens.
In general, MoE models are faster in inference than their total parameter count would suggest. This is because they use relatively fewer parameters for each input. We found that DBRX is no exception in this regard. DBRX's inference throughput is 2 to 3 times higher than that of a non-MoE model with 132B parameters.
Inference efficiency and model quality are often trade-offs: larger models typically achieve higher quality, but smaller models are more efficient in inference. Using MoE architecture can achieve better model quality and inference efficiency than dense models usually provide. For example, DBRX outperforms LLaMA2-70B in quality, and due to having approximately half the number of active parameters, DBRX's inference throughput is twice that of LLaMA2-70B (Figure 2). Mixtral is another point on the improved Pareto frontier achieved by MoE models: it is smaller than DBRX, so it scores lower in quality but has higher inference throughput. Users of the Databricks base model API can see DBRX achieving 150 tokens per second on our optimized model service platform, using 8-bit quantization.
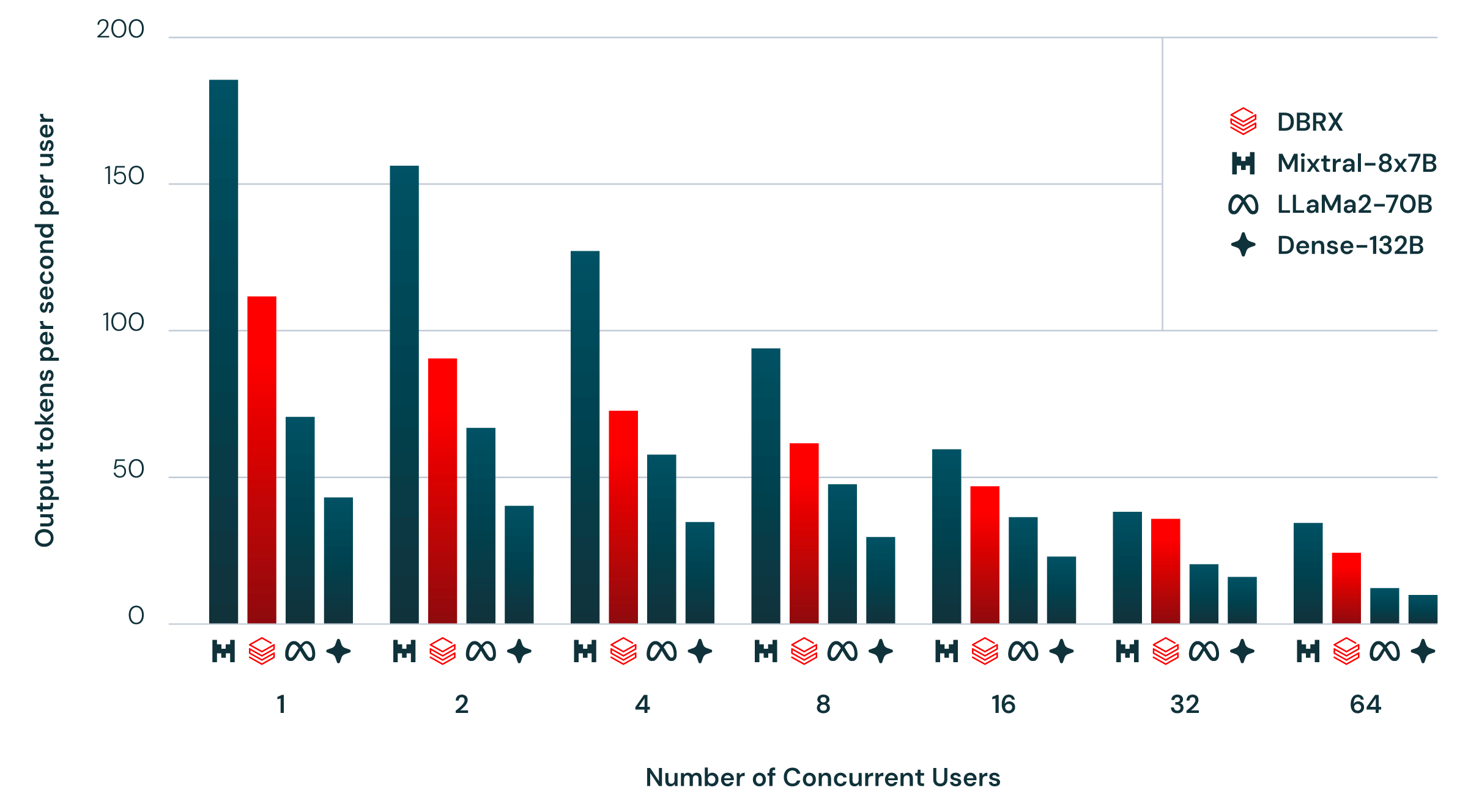
Figure 2. Inference throughput for various model configurations using NVIDIA TensorRT-LLM at 16-bit precision on our optimized service infrastructure. Models run in tensor parallelism across the nodes. Input prompts contain approximately 2000 prompt tokens, and we generate 256 output tokens. A new user is generated every second.
How We Built DBRX¶
DBRX was trained on a 3.2Tbps Infiniband connected by 3072 NVIDIA H100s. The main processes for building DBRX—including pre-training, post-training processing, evaluation, red teaming, and improvements—were conducted over three months. This was based on several months of scientific and dataset research and scaling experiments at Databricks, not to mention Databricks' years of experience in LLM development, including the MPT and Dolly projects, as well as the thousands of models we have built and deployed in production with our customers.
To build DBRX, we utilized the same Databricks toolkit available to our customers. We used Unity Catalog to manage and govern our training data. We explored this data using newly acquired Lilac AI. We processed and cleaned the data using Apache Spark™ and Databricks notebooks. We trained DBRX using an optimized version of our open-source training library: MegaBlocks, LLM Foundry, Composer, and Streaming. We managed large-scale model training and fine-tuning across thousands of GPUs using Mosaic AI Training services. We recorded our results using MLflow. We collected human feedback through Mosaic AI Model Serving and Inference Tables to improve quality and safety. We manually experimented with models using the Databricks Playground. We found that Databricks tools excel in their respective uses and that we benefit from them being part of a unified product experience.
Getting Started with DBRX on Databricks¶
If you want to start using DBRX immediately, you can easily access it through Databricks Mosaic AI Foundation Model APIs. You can get started quickly with our pay-as-you-go pricing and query the model through our AI Playground chat interface. For production applications, we offer a provisioned throughput option to provide performance guarantees, support fine-tuned models, and ensure additional safety and compliance. To privately host DBRX, you can download the model from the Databricks Marketplace and deploy it on Model Serving.
Conclusion¶
At Databricks, we believe that every enterprise should be able to take control of its data and destiny in the emerging GenAI world. DBRX is a core pillar of our next-generation GenAI products, and we look forward to the exciting journey our customers will take as they leverage the capabilities of DBRX and the tools we used to build it. Over the past year, we have trained thousands of LLMs with our customers. DBRX is just one example of the powerful and efficient models that Databricks builds, suitable for a variety of applications, from internal functionalities to our customers' ambitious use cases.
For any new model, the journey of DBRX is just the beginning; the best work will be done by those who build on it: enterprises and the open community. This is just the beginning of our work on DBRX, and you should expect more results to come.
Contributions¶
The development of DBRX is led by the Mosaic team, which previously built the MPT model series and collaborated with dozens of engineers, lawyers, procurement and finance experts, project managers, marketers, designers, and other contributors across various departments at Databricks. We thank our colleagues, friends, families, and communities for their patience and support over the past months.
In creating DBRX, we stand on the shoulders of giants in the open and academic communities. By making DBRX publicly available, we hope to give back to the community and look forward to building greater technologies together in the future. In this context, we are especially grateful for the work and collaboration of Trevor Gale and his MegaBlocks project (Trevor's PhD advisor is Databricks CTO Matei Zaharia), the PyTorch team and the FSDP project, NVIDIA and the TensorRT-LLM project, the vLLM team and project, EleutherAI and their LLM evaluation project, Daniel Smilkov and Nikhil Thorat from Lilac AI, and our friends at the Allen Institute for Artificial Intelligence (AI2) for their work and collaboration.